CLF-C02 DevOps, Storage, database

AWS CodePipeline
- 기본적으로 빠르고 안정적인 애플리케이션 및 인프라 업데이트를 위해 릴리스 파이프라인을 자동화 도구
AWS CodeStar (like vscode + jenkins)
- 애플리케이션 코드 코딩, 구축, 테스트 및 배포를 위한 전체 개발 및 지속적인 전달 도구 체인(CI/CD) 을 제공
- Atlassian JIRA Software에서 제공하는 통합 문제 추적 기능을 포함한 프로젝트 관리 대시보드가 함께 제공
AWS CodeCommit (like github)
- 기업이 안전하고 확장성이 뛰어난 프라이빗 Git 리포지토리
AWS CodeBuild (like jenkins)
- 소스 코드를 컴파일하고, 테스트를 실행하고, 배포할 준비가 된 소프트웨어 패키지를 생성하는 완전 관리형 빌드 서비스
스토리지 및 데이터베이스
Instance Store and Amazon Elastic Block Store (Amazon EBS)
Instance Store
-
블록 수준 스토리지 볼륨은 물리적 하드 드라이브처럼 동작
-
인스턴스 스토어는 EC2 인스턴스에 "임시" 블록 수준 스토리지를 제공
-
인스턴스가 종료되면 인스턴스 스토어의 데이터가 손실됨
Amazon Elastic Block Store (Amazon EBS)
-
Amazon EC2는 인스턴스에서 사용할 수 있는 블록 수준 스토리지 볼륨을 제공하는 서비스
-
최대 16TiB 크기, 기본 SSD 제공, HDD 옵션으로 제공
-
EC2 인스턴스를 중지 또는 종료하더라도 연결된 EBS 볼륨의 모든 데이터를 사용 가능
-
EBS Volume은 보존해야 하는 데이터를 위한 것이므로 데이터 백업이 중요
- Amazon EBS Snapshot을 생성하여 EBS 볼륨을 증분 백업 가능
EBS Shopshot
- EBS 스냅샷은 증분 백업이다.
- 처음 볼륨을 백업하면 모든 데이터가 복사됨
- 이후의 백업에서는 가장 최근의 스냅샷 이후 변경된 데이터 블록만 저장
- 증분 백업은 백업이 실행될 때마다 스토리지 볼륨의 모든 데이터가 복사되는 전체 백업과는 다름
Amazon Simple Storage Service (Amazon S3)
객체 스토리지 (Object Storage)
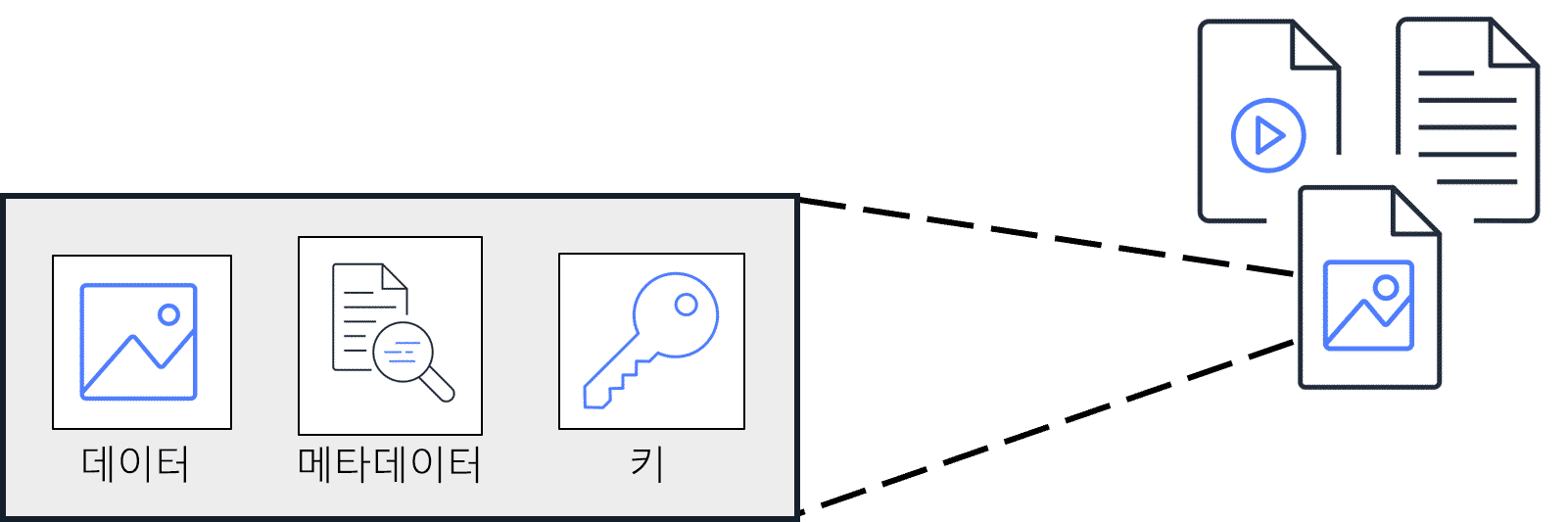
- 객체 스토리지에서 각 객체는 데이터, 메타데이터, 키로 구성
- 블록 스토리지에서 파일을 수정하면 변경된 부분만 업데이트 되지만, 객체 스토리지에서 파일을 수정하면 전체 객체가 업데이트됨
Amazon Simple Storage Service (Amazon S3)
- Amazon Simple Storage Service는 객체 수준 스토리지를 제공하는 서비스
- 데이터를 버킷에 객체로 저장
- 이미지, 동영상, 테스트 파일등 모든 유형의 파일을 업로드 가능
- S3의 저장공간을 무제한으로 제공
- 단, 저장할 수 있는 객체의 최대 파일 크기는 5TB 임
- S3에 파일을 업로드할 때 권한을 설정하여 파일에 대한 표시 여부 및 액세스를 제어할 수 있음.
- S3 버전 관리 기능을 사용하여, 시간 경과에 따른 객체 변경 사항을 추적 가능
Amazon S3 Storage Class
-
S3는 사용한 만큼 비용 지불
-
S3 스토리지 클래스를 선택할 때 다음 두가지 요소를 고려
- 데이터를 검색할 빈도
- 필요한 데이터 가용성
S3 Standard
- 자주 액세스 하는 데이터용으로 설계
- 최소 3개의 가용 영역에 데이터를 저장
- 고가용성을 제공
S3 Standard-Infrequent Access (S3 Standard-IA)
- 자주 액세스하지 않는 데이터에 이상적
- S3와 비슷하지만 스토리지 가격은 더 저럼, 검색 가격은 더 높음
- 최소 3개의 가용 영역에 데이터를 저장
S3 One Zone-Infrequnt Access (S3 One Zone-IA)
- 단일 가용성에 데이터를 저장
- S3 Standard-IA보다 낮은 스토리지 가격
- 스토리지 비용 절감 또는 장애가 발생해도 손쉽게 재현 가능한 경우 사용
S3 Intelligent-Tiering
- 액세스 패턴을 알 수 없거나 자주 변화하는 데이터에 이상적
- 객체당 소량의 월별 모니터링 및 자동화 요금을 부과
- 사용자가 30일 연속 객체에 액세스 하지 않으면 자동으로 S3 Standard-IA로 이동
- S3 Standard-IA 에 저장된 객체 액세스시 S3 Standard로 이동
S3 Glacier Instant Retrieval
- 즉각적인 액세스가 필요한 아키이브 데이터에 적합
- 몇 밀리초 만에 객체 검색 가능
- S3와 동일한 성능으로 검색 가능
S3 Glacier Flexible Retrieval
- 데이터 보관용으로 설계된 저비용 스토리지
- 객체를 몇 분에서 몇 시간 이내에 검색
- 검색 보장 시간 : 1분 - 12시간
S3 Glacier Deep Archive
- 가장 저렴한 객체 스토리지 클래스로 보관에 적합
- 12시간 이내에 객체를 검색
- 일년에 한두번 액세스 되는 데이터의 장기 보존 및 디지털 보존을 지원
- 검색시간 : 12 - 48시간
- 모든 객체가 최소한 3개의 지리적으로 분산된 가용영역에 복제되고 저장됨
S3 Outposts
- Amazon S3 Outposts에 S3 버킷을 생성
- AWS Outposts에 더 쉽게 데이터를 검색, 저장 및 액세스
- 온프레미스 AWS Outposts 환경에 객체 스토리지를 제공
Amazon Elastic File System (Amazon EFS)
File Storage
- 파일 스토리지에서는 여러 클라이언트가 공유 파일 폴더에 저장된 데이터에 엑세스할 수 있다.
- 이 접근 방식에서는 스토리지 서버가 블록 스토리지를 로컬 파일 시스템과 함께 사용하여 파일을 구성
- 클라이언트는 파일 경로를 통해 데이터에 액세스
- 파일 스토리지는 많은 수의 서비스 및 리소스가 동시에 동일한 데이터에 액세스해야 하는 사용 사례에 이상적
- Amazon Elastic File System (Amazon EFS) 은 AWS 클라우드 서비스 및 온프레미스 리소스와 함께 사용되는 확장 가능한 파일 시스템
Amazon EBS 와 Amazon EFS 비교
Amazon EBS
- Amazon EBS 볼륨은 단일 가용 영역에 데이터를 저장
- 한개의 EC2인스턴스의 접근 허용
- Amazon EC2 인스턴스를 EBS 볼륨에 연결하려면 Amazon EC2 인스턴스와 EBS 볼륨 모두 동일한 가용 영역에 상주
Amazon EFS
- Amazon EFS는 리전별 서비스, 여러 가용 영역에 걸쳐 데이터를 저장
- Amazon EFS는 최대 수천 개의 Amazon EC2 인스턴스 접근 허용
- 중복 스토리지를 사용하면 파일 시스템이 위치한 리전의 모든 가용 영역에서 동시에 데이터에 액세스 가능
- 온프레미스 서버는 AWS Direct Connect를 사용하여 Amazon EFS에 액세스 가능
Amazon Relational Database Service (Amazon RDS)
관계형 데이터 베이스
- 관계형 데이터베이스에서는 데이터가 다른 데이터 부분과 관련된 방식으로 저장
- **정형 쿼리 언어(SQL)**를 사용하여 데이터를 저장하고 쿼리
Amazon Relational Database Service
-
Amazon RDS는 AWS 클라우드에서 관계형 데이터베이스를 실행할 수 있는 서비스
-
Amazon RDS는 하드웨어 프로비저닝, 데이터베이스 설정, 패치 적용 백업과 같은 작업을 자동화하는 관리형 서비스
-
Amazon RDS를 다른 서비스와 통합하면 AWS Lambda를 사용하여 서버리스 애플리케이션에서 데이터베이스를 쿼리하는 등 비즈니스 및 운영 요구 사항을 충족 가능
-
다양한 보안 옵션 제공
- Amazon RDS 데이터베이스 엔진이 저장 시 암호화(데이터가 저장되는 동안 데이터를 보호)
- 전송 중 암호화(데이터를 전송 및 수신하는 동안 데이터를 보호)를 제공
Amazon RDS 데이터 엔진
-
지원되는 데이터베이스 엔진
- Amazon Aurora
- PostgreSQL
- MySQL
- MariaDB
- Oracle Database
- Microsoft SQL Server
Amazon Aurora
- Amazon Aurora는 엔터프라이즈급 관계형 데이터베이��스
- 이 데이터베이스는 MySQL 및 PostgreSQL 관계형 데이터베이스와 호환
- 워크로드에 고가용성이 필요한 경우 Amazon Aurora를 고려, 장애를 자동 복구
- 이 데이터베이스는 6개의 데이터 복사본을 3개의 가용 영역에 복제하고 지속적으로 Amazon S3에 데이터를 백업
Amazon DynamoDB
비관계형 데이터베이스
-
비관계형 데이터베이스에서는 테이블
-
비관계형 데이터베이스의 구조적 접근 방식 중 한 유형은 키-값 페어
- 키-값 페어에서는 데이터가 항목(키)으로 구성되고 항목은 속성(값)
- 속성을 데이터의 여러 기능으로 생각하면 됨
-
키-값 데이터베이스에서는 언제든지 테이블의 항목에서 속성을 추가하거나 제거할 수 있습니다.
-
테이블의 모든 항목에 동일한 속성이 있어야 하는 것은 아닙니다.
-
자체 복구 DB 아님
Amazon DynamoDB
-
Amazon DynamoDB는 키-값 데이터베이스 서비스
-
모든 규모에서 한 자릿수 밀리초의 성능을 제공
-
DynamoDB 기능
- DynamoDB는 서버리스이므로 서버�를 프로비저닝, 패치 적용 또는 관리할 필요가 없음
- 소프트웨어를 설치, 유지 관리, 운영할 필요도 없음
-
자동 크기 조정
- 데이터베이스 크기가 축소 또는 확장되면 DynamoDB는 용량 변화에 맞춰 자동으로 크기를 조정하면서도 일관된 성능을 유지
- 크기를 조정하는 동안에도 고성능이 필요한 사용 사례에 적합한 선택
- 하루 최대 100조개의 요청으로 확장 가능
-
자체 복구 DB 아님
Amazon Redshift (DB)
- Amazon Redshift는 빅 데이터 분석에 사용할 수 있는 데이터 웨어하우징 서비스
- 이 서비스는 여러 원본에서 데이터를 수집하여 데이터 간의 관계 및 추세를 파악하는 데 도움이 되는 기능을 제공
- 자체 복구 DB 아님
AWS Database Migration Service (AWS DMS)
-
AWS Database Migration Service (AWS DMS)는 관계형 데이터 베이스, 비관계형 데이터 베이스 및 기타 유형의 데이터 저장소를 마이그레이션할 수 있는 서비스
-
AWS DMS를 사용하면 원본 데이터베이스와 대상 데이터베이스 간에 데이터를 이동
-
원본 데이터베이스와 대상 데이터 베이스는 유형이 동일할 필요가 없음.
- MS SQS - Amazon Aurora PostgreSQL 등
-
마이그레이션하는 동안 원본 데이터베이스가 계속 작동하므로 데이터베이스를 사용하는 애플리케이션의 가동 중지 시간을 줄일 수 있음.
AWS DMS의 사용 사례
-
개발 및 테스트 데이터베이스 마이그레이션
- 프로덕션 사용자에게 영향을 주지 않고 개발자가 프로덕션 데이터에서 애플리케이션을 테스트할 수 있도록 지원
-
데이터베이스 통합
- 여러 데이터베이스를 단일 데이터베이스로 결합
-
연속 복제
- 일회성 마이그레이션을 수행하는 것이 아니라 데이터의 진행 중 복제본을 다른 대상 원본으로 전송
추가 데이터 베이스 서비스
Amazon DocumentDB
- MongoDB 워크로드를 지원하는 문서 데이터베이스 서비스
Amazon Neptune
- 그래프 데이터베이스 서비스
- Amazon Neptune을 사용하여 추천 엔진, 사기 행위 탐지, 지식 그래프와 같이 고도로 연결된 데이터 세트로 작동하는 애플리케이션을 빌드하고 실행 가능
Amazon Quantum Ledger Database (Amazon QLDB)
- 원장 데이터베이스 서비스
- Amazon QLDB를 사용하여 애플리케이션 데이터에 발생한 모든 변경 사항의 전체 기록을 검토
- 감사용 데이터 변경 불가능한 데이터 베이스
Amazon Managed Blockchain
- 오픈 소스 프레임워크를 사용하여 블록체인 네트워크를 생성하고 관리하는 데 사용할 수 있는 서비스
- Blockchain은 여러 당사자가 중앙 기관 없이 거래를 실행하고 데이터를 공유할 수 있는 분산형 원장 시스템
Amazon ElastiCache
-
자주 사용되는 요청의 읽기 시간을 향상시키기 위해 데이터베이스 위에 캐싱 계층을 추가하는 서비스
-
지원 서비스 유형
- Redis
- Memcached
Amazon DynamoDB Accelerator
- DynamoDB용 인 메모리 캐시
- 응답 시간을 한 자릿수 밀리초에서 마이크로초까지 향상 가능
Amazon EMR (분석 서비스)
-
기업, 연구원, 데이터 분석가 및 개발자가 방대한 양의 데이터를 쉽고 비용 효과적으로 처리할 수 있도록 지원하는 웹 서비스
-
기계 학습, 데이터 변환(ETL), 금융 및 과학 시뮬레이션, 생물정보학, 로그 분석, 딥 러닝을 포함한 광범위한 빅 데이터 문제를 안전하고 안정적으로 처리
-
종류
- Hadoop 기반의 EMR
- Apache Spark 기반의 EMR